
What is SRE Uptime and Why It Matters for SaaS Companies in 2025
- Nitin Yadav
- Knowledge
About

Boost SaaS reliability with SRE uptime. Learn why uptime matters in 2025 and how DevOps for SaaS with AWS, Azure & GCP ensures 99.99% availability.
Industries
- AWS uptime, Azure SaaS, DevOps for SaaS, enterprise SaaS reliability, GCP SaaS reliability, multi-cloud SaaS, reduce SaaS downtime, SaaS automation, SaaS monitoring, SaaS reliability, SaaS uptime, Site Reliability Engineering, SRE uptime
Share Via
The SaaS industry is projected to reach over $300 billion by 2025. With this explosive growth comes fierce competition. Features may attract attention, but what keeps customers loyal is something far less glamorous: uptime.
Downtime is a silent killer for SaaS businesses. A payment gateway going offline during a sales event, a CRM crashing during peak hours, or a project management tool freezing in the middle of deadlines, all these failures directly erode trust and revenue.
This is why more SaaS companies are adopting SRE (Site Reliability Engineering) frameworks for uptime. Instead of treating reliability as a reactive IT concern, SRE makes uptime measurable, predictable, and engineered into the DNA of SaaS platforms.
In this deep dive, we’ll cover:
- The definition of SRE uptime.
- Why uptime is mission-critical for SaaS in 2025.
- The business cost of downtime.
- How DevOps for SaaS and SRE complement each other.
- The pillars of achieving uptime at scale.
- Real-world case studies.
- What the future of SRE uptime looks like.
What is SRE Uptime?
At its core, SRE uptime is the percentage of time a SaaS service is available and performing as expected, backed by Site Reliability Engineering practices. Unlike traditional uptime monitoring, SRE makes reliability proactive through clear metrics and processes.
The Framework:
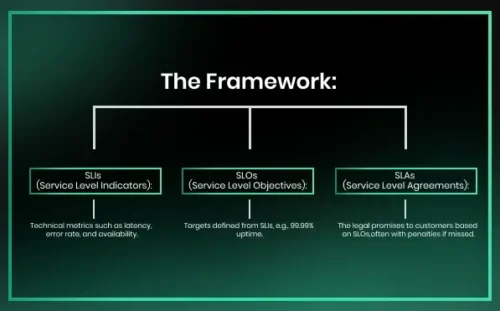
- SLIs (Service Level Indicators): Technical metrics such as latency, error rate, and availability.
- SLOs (Service Level Objectives): Targets defined from SLIs, e.g., 99.99% uptime.
- SLAs (Service Level Agreements): The legal promises to customers based on SLOs, often with penalties if missed.
Example in Numbers:
- 99.9% uptime (three nines): ~8.7 hours downtime/year.
- 99.99% uptime (four nines): ~52 minutes downtime/year.
- 99.999% uptime (five nines): ~5 minutes downtime/year.
For a SaaS business with 50,000 paying users, the gap between three nines and four nines could mean millions in saved revenue and retained customers.
Why Uptime Matters More Than Ever in 2025
The SaaS landscape has shifted dramatically. Customers expect services to be always available whether they’re logging in from New York, Bangalore, or Berlin. In 2025, uptime isn’t just about convenience; it’s a growth driver.
1. Customer Retention
SaaS products live on recurring revenue. When downtime happens repeatedly, customers churn quickly. According to a 2024 survey, 42% of SaaS users switched platforms due to reliability issues.
2. Revenue Protection
Downtime = zero transactions. For payment SaaS or B2B platforms, even one hour of downtime can cause revenue losses in the millions.
3. Enterprise Deals and SLAs
Large enterprises demand uptime guarantees before signing contracts. Without a proven 99.99% uptime SLA, many SaaS providers simply won’t qualify.
4. Competitive Differentiation
In saturated markets, performance becomes the differentiator. A product with fewer features but better uptime will often win the enterprise client.
The Business Impact of Downtime
Let’s put the cost into perspective:
- Direct Losses: Gartner estimates the average cost of downtime at $5,600 per minute.
- Operational Impact: Outages can disrupt customer workflows, leading to lost productivity.
- Reputation Damage: A SaaS company trending on social media for outages may never recover its credibility.
- Churn & CAC: Losing customers due to downtime forces companies to spend 5x more on acquiring new ones.
For a SaaS company doing $20M ARR, even a 0.5% increase in churn caused by downtime can wipe out $100,000+ annually.
How DevOps for SaaS Enhances SRE Uptime
DevOps for SaaS focuses on delivering software quickly and reliably. SRE ensures that reliability targets aren’t compromised in pursuit of speed.
DevOps Brings:
- Continuous Integration/Continuous Deployment (CI/CD).
- Automated testing and faster releases.
- Culture of shared responsibility between development and operations.
SRE Adds:
- Defined error budgets and reliability objectives.
- Monitoring and observability frameworks.
- Incident management processes to reduce MTTR (Mean Time to Recovery).
Together:
The fusion of DevOps and SRE enables SaaS companies to deploy features 10 times faster while maintaining 99.99% uptime. This is particularly crucial in multi-cloud setups spanning AWS, Azure, and GCP.
The Pillars of Achieving SRE Uptime
1. Monitoring & Observability
You can’t improve what you can’t measure. SaaS companies must track not only downtime but also performance trends.
- Unified dashboards pulling from AWS CloudWatch, Azure Monitor, and GCP Cloud Monitoring.
- Distributed tracing to identify bottlenecks.
- Proactive monitoring with synthetic tests.
2. Automation
Manual fixes take too long. Automation ensures issues are resolved before customers even notice.
- Auto-scaling for traffic spikes.
- Self-healing systems that restart crashed services.
- CI/CD rollback when deployments introduce errors.
3. Error Budgets
Error budgets help strike a balance between innovation and stability. For example, a 99.99% uptime target allows 52 minutes of annual downtime. Once the budget is exhausted, new releases are paused until reliability improves.
4. Incident Response
SRE teams maintain playbooks for outages. With automation, alerts trigger workflows that significantly reduce downtime.
5. Multi-Cloud Redundancy
Relying on one provider is risky. Spreading workloads across Azure, AWS, and GCP ensures resilience and compliance with regional regulations.
Case Study: SaaS Startup Boosts Uptime with SRE
Background:
A mid-sized SaaS provider offering workflow tools relied on a single AWS region. Outages during peak usage frustrated enterprise customers.
Challenges:
- Downtime caused churn among B2B clients.
- Lack of unified monitoring.
- Manual interventions slowed recovery.
Solution:
- Adopted multi-cloud deployments across Azure + GCP.
- Implemented centralized observability.
- Automated failover between regions and rollback in CI/CD pipelines.
Results:
- Uptime improved from 99.5% → 99.99%.
- Churn reduced by 18%.
- Enterprise contracts worth $2M signed based on uptime SLA guarantees.
Future of SRE Uptime in SaaS
The next evolution of SaaS reliability will be defined by:
- AI-Driven Observability
Predictive models detecting failures before they occur. - Self-Healing Multi-Cloud
Workloads that autonomously shift between Azure, AWS, and GCP. - Compliance-First Reliability
Industries like healthcare and finance require mandated 99.99% uptime. - DevOps + SRE Convergence
No longer separate practices a unified approach where speed and reliability are engineered together. - FinOps Integration
Balancing uptime goals with cost optimization, ensuring companies don’t overspend for marginal improvements.
Conclusion
SaaS growth is no longer about who ships the most features. In 2025, it’s about who stays online the longest.
SRE uptime, reinforced by DevOps for SaaS, provides the framework to deliver continuous reliability in a multi-cloud world. Companies that embrace SRE will not only reduce churn but also unlock enterprise growth and protect revenue.
At SquareOps, we help SaaS businesses achieve:
- 99.99% uptime with SRE-driven practices.
- Automated monitoring and observability.
- Multi-cloud resilience across AWS, Azure, and GCP.
- DevOps pipelines are designed for speed and stability.
Ready to achieve enterprise-grade uptime?
Book a Free SaaS Reliability Audit with SquareOps
Frequently asked questions
SRE uptime refers to the availability and reliability of a SaaS application, measured using Site Reliability Engineering principles like SLOs, SLIs, and SLAs. It ensures platforms remain online 24/7 to meet customer expectations.
In 2025, SaaS customers demand always-on services. High SRE uptime reduces churn, protects revenue, improves customer trust, and is often required in enterprise SLAs
Uptime is measured using service-level indicators (SLIs) such as latency, error rates, and availability. Targets are defined as service-level objectives (SLOs), such as 99.99% uptime, which translates to less than 1 hour of downtime per year.
An uptime SLA is a contractual promise to customers, while SRE uptime is the engineering framework used to achieve that SLA through monitoring, automation, and error budgets.
DevOps accelerates feature delivery with CI/CD pipelines, while SRE enforces reliability through monitoring and automation. Together, they help SaaS companies scale without compromising uptime.
An error budget is the maximum acceptable downtime or failure a SaaS system can have while still meeting its reliability targets. It balances innovation speed with system stability.
Deploying across AWS, Azure, and Google Cloud Platform reduces dependency on a single provider. Multi-cloud redundancy improves resilience, compliance, and SRE uptime.
Automation reduces human error and downtime by enabling auto-scaling, self-healing services, CI/CD rollbacks, and automated incident responses across SaaS platforms.
Failing to meet uptime SLAs can result in financial penalties, customer churn, reputational damage, and lost enterprise contracts. This is why achieving SRE uptime is critical.
SquareOps implements SRE-driven practices, DevOps automation, and multi-cloud monitoring across AWS, Azure, and GCP to help SaaS companies guarantee enterprise-grade uptime and scalability.
Related Posts

Comprehensive Guide to HTTP Errors in DevOps: Causes, Scenarios, and Troubleshooting Steps
- Blog

Trivy: The Ultimate Open-Source Tool for Container Vulnerability Scanning and SBOM Generation
- Blog

Prometheus and Grafana Explained: Monitoring and Visualizing Kubernetes Metrics Like a Pro
- Blog

CI/CD Pipeline Failures Explained: Key Debugging Techniques to Resolve Build and Deployment Issues
- Blog

DevSecOps in Action: A Complete Guide to Secure CI/CD Workflows
- Blog

AWS WAF Explained: Protect Your APIs with Smart Rate Limiting
- Blog