
Differences between Site Reliability Engineering and DevOps Explained
- Nitin Yadav
- Knowledge
About

Understand Site Reliability Engineering and DevOps differences in focus and goals. Boost system reliability. Click to enhance software delivery.
Industries
- AWS, SRE
Share Via
Overview
We demand reliability from the software and applications we use. But what are the essential ingredients that make these businesses dependable, particularly in the current climate of maximizing efficiency?
The simple yet straightforward answer is Site Reliability Engineering (SRE) and DevOps. Together, these critical components keep digital businesses running smoothly.
- By 2027, 75% of enterprises are expected to implement SRE practices across their organizations, a dramatic increase from just 10% in 2022.
- An impressive 77% of organizations have already adopted DevOps practices to streamline their software deployment processes.
Eager to know why these practices could be game-changers for any tech-driven business? Let’s get you started!
What Exactly Is DevOps?
DevOps is a set of practices that bring development and operations teams together to work more efficiently. It focuses on automating and improving the processes of software development, testing, and deployment.
Here’s a simple example to make this idea clear:
Netflix uses DevOps practices to deploy thousands of daily updates to ensure polished service for millions of users globally without errors. This is because its developers automate the deployment of new features by implementing CI/CD pipelines.
The key goal of DevOps is to deliver high-quality software quickly and reliably, but let’s see what it also focuses on.
Goals of DevOps
Highlighted in the table below are some of its intended goals:
Purpose | Description |
| |
Collaboration and communication |
|
Quality assurance |
|
Infrastructure as Code (IaC) | Allows teams to manage infrastructures via code, enhancing consistency and speed in setting up and tearing down environments |
Monitoring and Feedback | Employs continuous monitoring and leverages feedback to quickly adapt and improve the software post-deployment |
Also, if you’re just getting started with DevOps, check out “Beginner’s Journey to Mastering DevOps Concepts”—a must-read!
With this clear understanding, let’s move on to its principles to better understand how DevOps frameworks work to achieve these objectives.
Core Principles of DevOps

DevOps has really transformed how teams work. It helps us collaborate better, streamline our processes, and get things done faster.
Let’s break it down:
CI/CD
CI/CD is all about integrating code changes into a shared repository frequently, followed by automated testing and deployment. This ensures that releases are quick, reliable, and require minimal manual work.
Here’s a real-time example:
At SquareOps, we helped Harappa Education improve their software delivery by putting efficient DevOps practices into action. By automating their CI/CD pipelines and improving team collaboration, we cut down deployment times and made their releases more reliable.
Curious about how we did it? Continue reading the full case study here.
Infrastructure as Code and Automated Testing
IaC allows teams to manage and provision infrastructure through code, improving consistency and speed. Automated testing ensures that code is thoroughly tested before deployment, reducing errors and improving software quality.
According to the 2023 DORA Report, high-performing organizations that implemented CI/CD saw a 46% increase in deployment speed and a 30% decrease in failure rates.
Cultural Emphasis on Collaboration and Agile Methodologies
DevOps promotes a strong culture of teamwork, where development and operations teams work closely together. This helps improve communication and speeds up problem-solving.
Plus, agile methodologies are key, as they focus on working in small, manageable stages. This allows teams to adapt to changes and continuously improve their processes quickly.
Now that we’ve covered DevOps, let’s explore SRE and how it complements these practices.
Understanding SRE Made Easy
On the other hand, Site Reliability Engineering (SRE) focuses on ensuring that software systems are highly reliable, scalable, and performant. It applies engineering practices to operations, emphasizing automation, incident management, and performance monitoring.
Simply put, Google employs SRE to ensure the reliability of its search engine and cloud services. By automating much of their incident management process, they can quickly respond to and resolve issues that affect system performance or availability. This approach helps maintain reliability, even during high-traffic periods.
But what are its additional goals? Read on to know in detail.
Goals of SRE
As organizations strive for improved reliability and performance, SRE plays a pivotal role in bridging development and operations.
Let’s explore the key goals of SRE:
Purpose | Description |
Enhances System Reliability | Focuses on creating ultra-reliable systems that ensure availability and performance, even under duress |
Incident Management | Develops robust plans to address failures swiftly and learn from them to prevent future issues |
Efficiency and Automation | Reduces toil by automating routine tasks, allowing engineers to focus on high-value activities |
Capacity Planning | Ensures effective resource management to maintain scalability and preparedness as demand grows |
Performance Monitoring | Maintains continuous oversight of systems to ensure optimal operation and user satisfaction |
Also read: Top 10 Site Reliability Engineering (SRE) Tools to Enhance System Reliability
Core Principles of SRE

SRE makes sure systems are reliable and easy to manage. Let’s see how it works using everyday examples to bring these complex ideas to life:
1. SLOs & SLIs
- Service level objectives (SLOs) are specific goals that companies aim to meet in terms of reliability and performance.
- Service level indicators (SLIs), on the other hand, are the metrics used to measure whether these goals are being achieved.
Imagine your favorite online store promising that its website will load within 3 seconds at least 98% of the time.
- Here, the 3-second load time is the SLO
- The percentage of times it actually loads within 3 seconds is the SLI.
2. Blameless Postmortems
Blameless postmortems are meetings where teams discuss what happened, why it happened, and how to prevent it in the future, focusing on improvement rather than fault.
That being said, when things go wrong, SRE emphasizes learning from the incident without blaming any individual.
Example: If a website crashes during a sale, the SRE team would investigate the cause and discuss how to better handle traffic spikes without pointing fingers at any team members.
3. Automation vs. Toil
SRE automates repetitive, manual tasks (known as toil) to free up time for more valuable work that improves the system.
If an engineer spends hours every week manually checking server logs for errors, automating this process with a script can save time and reduce the chance of human error.
For more in-depth information about the added advantages of SRE, give this a read.
Here comes the main segment. We’ll explore the key differences between SRE and DevOps and how these two practices compare and complement each other.
Tools and Techniques
Both SRE and DevOps rely on specialized tools to execute their tasks effectively.
Starting with SRE tools, businesses can leverage various monitoring, automation, and incident management tools that proactively monitor and manage complex cloud infrastructures. This ensures high system availability and performance across multiple cloud platforms like AWS, Azure, and Google Cloud.
SquareOps & SRE Tools
At SquareOps, we help businesses set up and maintain reliable, scalable, and high-performance systems using some of the best SRE tools out there. Our goal is to make sure your infrastructure runs smoothly, no matter how complex it gets.
- Monitoring and Observability – Prometheus & Grafana
We use Prometheus and Grafana to provide powerful monitoring and observability for our clients. This combination offers a real-time view of your system’s health.
We also integrate Atmosly, a platform designed with a security-first approach, into your development pipeline. It helps identify vulnerabilities early, allowing for quick remediation improving the overall security posture of your applications. On top of that, Atmostly seamlessly connects with observability tools like Prometheus, Grafana, and the ELK stack, enabling more efficient management and optimization of your cloud infrastructure.
- Incident Management – PagerDuty
When things go wrong, you need the right tools to jump into action. That’s why we use PagerDuty for incident management.
This tool helps us set up automated alerts and escalation paths to ensure the right people are notified as soon as something happens. We’ve used PagerDuty to reduce downtime for clients, keeping operations running smoothly even during critical incidents.
- Cloud Platforms – AWS
At SquareOps, we leverage AWS to manage and scale cloud infrastructure for our clients. We ensure that your cloud environment is secure, scalable, and cost-effective—whether you’re running microservices, containers, or serverless applications.
Being an AWS advanced consulting partner, we help businesses migrate to AWS with minimal friction.
AWS Partner Competencies
SquareOps has earned AWS Competency recognition in specialized areas like DevOps and cloud operations, optimizing our client’s AWS infrastructure. Whether you’re a small startup or a large enterprise, we’ve got the expertise to set up a robust, efficient system for you.
Next, let’s explore some of the popular DevOps tools.
DevOps Tools
SquareOps applications are built, tested, and deployed using a combination of popular tools. This allows for efficient and repeatable deployments across environments.
- CI/CD Pipelines – Jenkins
At SquareOps, we help set up a simple and efficient CI/CD pipeline using Jenkins for hundreds of microservices running in Kubernetes on AWS EKS.
Our approach is designed to be developer-friendly, straightforward, and easy to maintain. Plus, it’s been proven effective in large-scale production deployments.
Want to see how it’s done? Check out our step-by-step guide for the entire setup here.
- IaC Tools – Terraform
With our Terraform IaC services, SquareOps streamlines and automates cloud infrastructure management. We develop reusable and modular Terraform configurations, supporting multi-cloud environments.
Our team implements best practices for Terraform state management, including remote state storage, state locking, and encryption, to maintain the integrity and security of your infrastructure state.
Here’s a real-time example.
SquareOps: A Comprehensive Terraform IaC Service Partner
Tompkins Robotics, a leading logistics and warehouse management provider in the U.S., partnered with SquareOps to migrate their applications to a containerized environment using AWS Elastic Kubernetes Service (EKS).
We utilized Terraform to automate the provisioning of AWS infrastructure and EKS clusters. This resulted in improved scalability, reduced deployment times, and enhanced operational efficiency.
As discussed above, both SRE and DevOps benefit from automation and collaboration tools. Let’s now examine how these two practices complement each other.
A Quick Comparison: SRE Vs. DevOps
While both aim to improve software delivery and system reliability, SRE and DevOps approach these goals from different angles.
Here’s how:
Aspect | SRE | DevOps |
Primary focus areas |
|
|
Team structure | Combines operations with engineering | Merges development with operations |
Metrics | Measures success with service levels | Looks at deployment speed and error rates |
Change management | Accepts risks to improve reliability | Aims to minimize risks in changes |
Problem solving | Automates to reduce manual tasks | Focuses on quick, iterative improvements |
Let’s wrap up by summarizing how they can work together to ultimately boost your business growth.
Why Choose SquareOps?
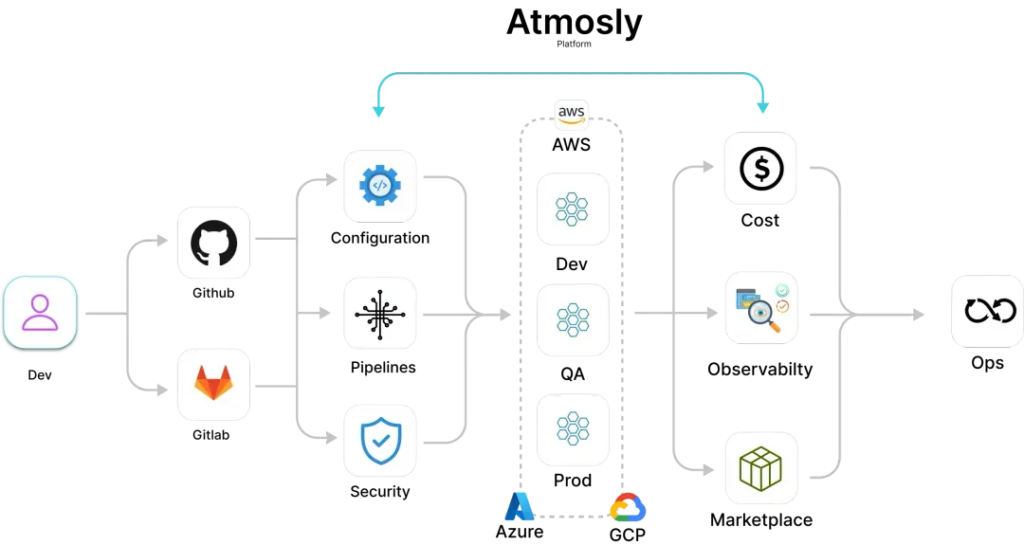
Looking to manage complex systems better and deliver high-quality services consistently?
Partnering with experts like SquareOps can make all the difference. Through Atmosly, our DevOps automation platform, we provide seamless integration of continuous delivery with system reliability practices.
Whether it’s enhancing cloud infrastructure, scaling services, or improving incident response, we can help streamline your operations, accelerate time-to-market, and optimize reliability.
In a recent case study, SquareOps helped a large e-commerce client reduce deployment times by 50% while improving system uptime by 40% using a combination of SRE principles and DevOps automation. This shows that Atmosly can greatly enhance your operational capabilities and ensure stability.
Ready to upgrade your infrastructure and improve reliability? Contact us today, and let us guide you through it!
Frequently asked questions
SRE is a discipline that incorporates aspects of software engineering and applies them to infrastructure and operations problems. The main goal is to create scalable and highly reliable software systems.
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) aimed at shortening the development life cycle and providing continuous delivery with high software quality.
SRE focuses on system reliability, while DevOps emphasizes collaboration and automation to speed up software delivery.
The main purpose of DevOps is to automate and streamline software delivery, improving speed and collaboration between development and operations teams.
CI/CD stands for Continuous Integration and Continuous Delivery, which means automating the process of integrating code changes and delivering them to production.
A software engineer builds applications, while a site reliability engineer ensures those applications run smoothly and reliably in production.
Platform engineering builds and manages the infrastructure, while DevOps focuses on improving collaboration and automating the software development lifecycle.
DevOps focuses on automating and improving software delivery, while engineering refers to the design and development of software systems.
Related Posts

Comprehensive Guide to HTTP Errors in DevOps: Causes, Scenarios, and Troubleshooting Steps
- Blog

Trivy: The Ultimate Open-Source Tool for Container Vulnerability Scanning and SBOM Generation
- Blog

Prometheus and Grafana Explained: Monitoring and Visualizing Kubernetes Metrics Like a Pro
- Blog

CI/CD Pipeline Failures Explained: Key Debugging Techniques to Resolve Build and Deployment Issues
- Blog

DevSecOps in Action: A Complete Guide to Secure CI/CD Workflows
- Blog

AWS WAF Explained: Protect Your APIs with Smart Rate Limiting
- Blog